
Instance-Optimal Estimation with Multiple LLM Judges on a Budget
Evaluating large language models increasingly relies on LLM-as-a-judge protocols, but such evaluations remain costly: different judges have different prices and reliabilities, and …
I am a final-year PhD candidate at the Kim Jaechul Graduate School of AI, KAIST, where I am very fortunate to be advised by Se-Young Yun (OSI Lab) and Chulhee “Charlie” Yun (OptiML Lab). I spent the summer of 2025 as a Research Scientist Intern at Adobe Research, San Jose, working with Branislav “Brano” Kveton, Anup Rao, Subhojyoti Mukherjee, Ryan A. Rossi, Sunav Choudhary, and Alexa Siu. Before my PhD, I earned my MSc from the same school, and a BSc in Mathematical Sciences and Computer Science (double major, cum laude), also from KAIST.
My research focuses primarily on interactive machine learning (online learning, bandits, RL, active learning), “theoretical aspects” of LLMs (e.g., alignment, reasoning), optimization theory, deep learning theory, and statistical analyses of large networks with an emphasis on community detection. More broadly, I am interested in all aspects of mathematical and theoretical AI, as well as related problems in mathematics and statistics.
I enjoy organizing seminars and workshops to foster Korea’s theoretical AI community (see Organizer). Outside of research, I am an avid violinist and perform as a first violinist with various amateur orchestras, including the KAIST Orchestra (KAO), PASSIONATE Orchestra, MDOP Orchestra, KAO-S, PROJECT Starlight, and PROJECT IDEA.
Feel free to reach out if you’d like to collaborate on any of my research topics, or just to connect! (Third-person bio here.)
PhD in Artificial Intelligence
2023 – Present
KAIST
MSc in Artificial Intelligence
2021 – 2023
KAIST
BSc in Mathematical Sciences & Computer Science
2017 – 2021 · cum laude
KAIST
Evaluating large language models increasingly relies on LLM-as-a-judge protocols, but such evaluations remain costly: different judges have different prices and reliabilities, and …
We revisit regularized regret minimization under full-information and bandit feedback, where a learner optimizes an objective of the form $\langle r, \pi \rangle - \eta^{-1} …

We present GL-LowPopArt, a novel Catoni-style estimator for generalized low-rank trace regression. Building on LowPopArt (Jang et al., 2024), it employs a two-stage approach -- …
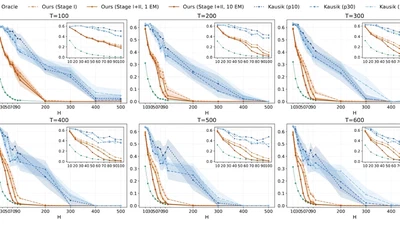
We study the problem of clustering T trajectories of length H, each generated by one of K unknown ergodic Markov chains over a finite state space of size S. The goal is to …
We consider the problem of *regularized* best-response max-regret minimization in online RLHF under general preferences and bandit feedback. While various regularizers are utilized …
Browse and filter all publications on the Publications page.
KAIST Seoul Campus, Building 9 (9508 & 9410)
85 Hoegi-ro, Dongdaemun-gu
Seoul 02455, Republic of Korea