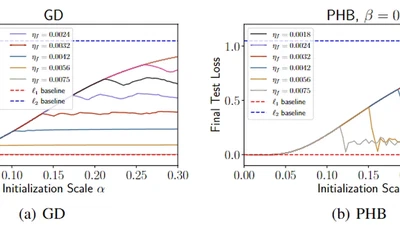
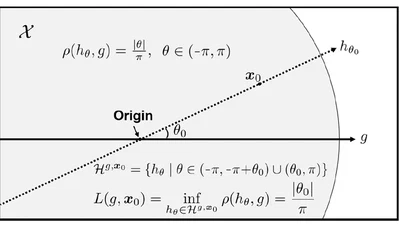
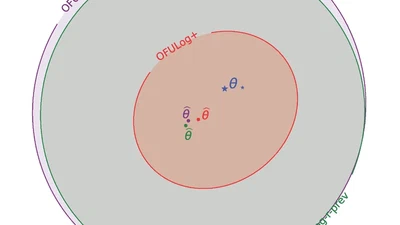
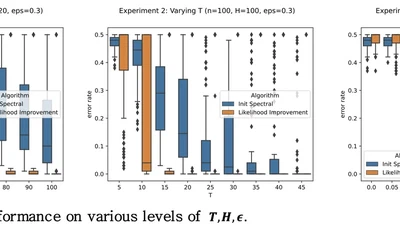
AdaSTaR: Adaptive Data Sampling for Training Self-Taught Reasoners
Self-Taught Reasoners (STaR), synonymously known as Rejection sampling Fine-Tuning (RFT), is an integral part of the training pipeline of self-improving reasoning Language Models …
woosung-koh