Instance-Optimal Estimation with Multiple LLM Judges on a Budget
Evaluating large language models increasingly relies on LLM-as-a-judge protocols, but such evaluations remain costly: different judges have different prices and reliabilities, and …
Evaluating large language models increasingly relies on LLM-as-a-judge protocols, but such evaluations remain costly: different judges have different prices and reliabilities, and …
We revisit regularized regret minimization under full-information and bandit feedback, where a learner optimizes an objective of the form $\langle r, \pi \rangle - \eta^{-1} …
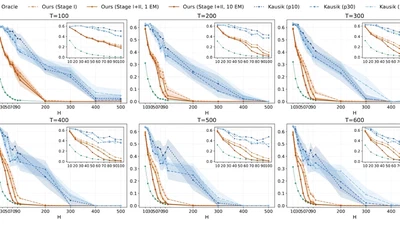
We study the problem of clustering T trajectories of length H, each generated by one of K unknown ergodic Markov chains over a finite state space of size S. The goal is to …

We present GL-LowPopArt, a novel Catoni-style estimator for generalized low-rank trace regression. Building on LowPopArt (Jang et al., 2024), it employs a two-stage approach -- …
We consider the problem of *regularized* best-response max-regret minimization in online RLHF under general preferences and bandit feedback. While various regularizers are utilized …
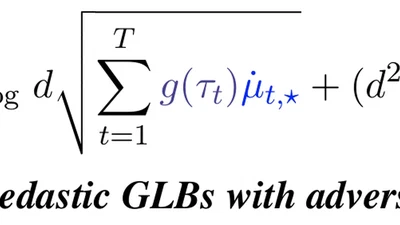
We consider the problem of heteroskedastic generalized linear bandits (GLBs) with adversarial corruptions, which subsumes various stochastic contextual bandit settings, including …

Inspired by recent advances in multi-task bandits, we propose a new problem setting called low-rank, hierarchical Gaussian linear bandits, which combines low-rank structure with …

Self-Taught Reasoners (STaR), synonymously known as Rejection sampling Fine-Tuning (RFT), is an integral part of the training pipeline of self-improving reasoning Language Models …
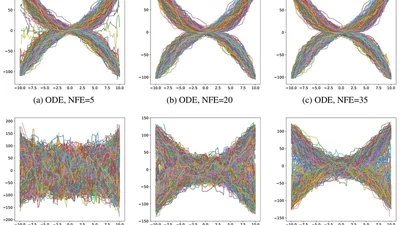
Recent advances in infinite-dimensional diffusion models have demonstrated their effectiveness and scalability in function generation tasks where the underlying structure is …
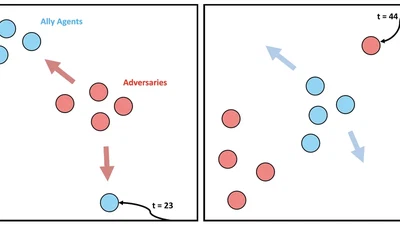
Multi-agent reinforcement learning has demonstrated significant potential in addressing complex cooperative tasks across various real-world applications. However, existing MARL …