Abstract
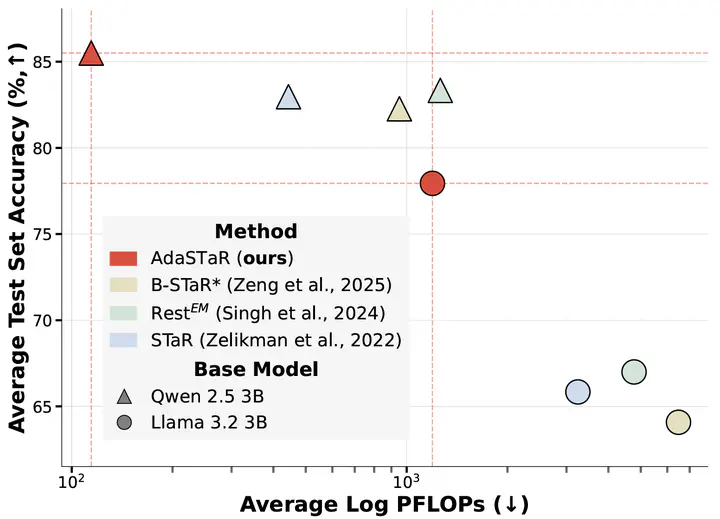
Self-Taught Reasoners (STaR), synonymously known as Rejection sampling Fine-Tuning (RFT), is an integral part of the training pipeline of self-improving reasoning Language Models (LMs). The self-improving mechanism often employs random observation (data) sampling. However, this results in trained observation imbalance; inefficiently over-training on solved examples while under-training on challenging ones. In response, we introduce Adaptive STaR (AdaSTaR), a novel algorithm that rectifies this by integrating two adaptive sampling principles: (1) Adaptive Sampling for Diversity: promoting balanced training across observations, and (2) Adaptive Sampling for Curriculum: dynamically adjusting data difficulty to match the model’s evolving strength. Across six benchmarks, AdaSTaR achieves best test accuracy in all instances (6/6) and reduces training FLOPs by an average of 58.6% against an extensive list of baselines. These improvements in performance and efficiency generalize to different pre-trained LMs and larger models, paving the way for more efficient and effective self-improving LMs.
Junghyun Lee
PhD Student
PhD student at GSAI, KAIST, jointly advised by Profs. Se-Young Yun and Chulhee Yun. Research focuses on interactive machine learning, particularly at the intersection of RLHF and preference learning, and statistical analyses of large networks, with an emphasis on community detection. Broadly interested in mathematical and theoretical AI and related problems in mathematics.