Abstract
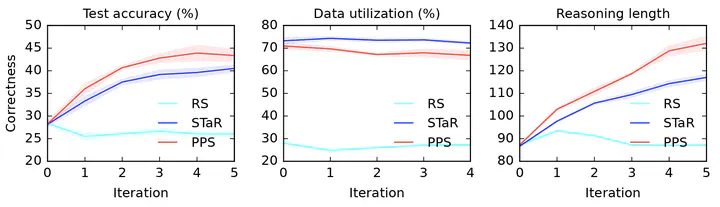
Large language models (LLMs) solve reasoning problems by first generating a rationale and then answering. We formalize reasoning as a latent variable model and derive a reward-based filtered expectation-maximization (FEM) objective for learning to reason. This view connects EM and modern reward-based optimization, and shows that the main challenge lies in designing a sampling distribution of rationales that justify correct answers. We instantiate and compare three sampling schemes: rejection sampling with a budget, self-taught reasoner (STaR), and prompt posterior sampling (PPS), which only keeps the rationalization stage of STaR that conditions on the correct answer in the prompt. We experiment with LLM-as-a-judge calibration and summarization from feedback tasks, where conditioning on the correct answer provides a strong guidance for generating rationales. Our experiments show the efficacy of PPS over other sampling schemes, and that the sampling scheme can have a significant impact on performance.
Junghyun Lee
PhD Student
PhD student at GSAI, KAIST, jointly advised by Profs. Se-Young Yun and Chulhee Yun. Research focuses on interactive machine learning, “theoretical perspectives” of LLMs, optimization theory, and statistical analyses of large networks with an emphasis on community detection. Broadly interested in mathematical and theoretical AI, as well asrelated problems in mathematics and statistics.