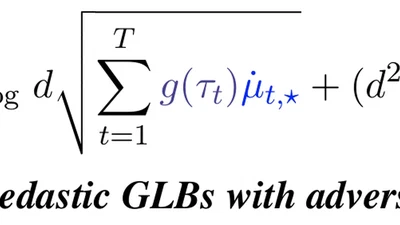Looking Through the Mirror: Minimax-Optimal Regularized Regrets in Online Learning and Bandits
We revisit regularized regret minimization under full-information and bandit feedback, where a learner optimizes an objective of the form $\langle r, \pi \rangle - \eta^{-1} …