Instance-Optimal Estimation with Multiple LLM Judges on a Budget
Evaluating large language models increasingly relies on LLM-as-a-judge protocols, but such evaluations remain costly: different judges have different prices and reliabilities, and …
Evaluating large language models increasingly relies on LLM-as-a-judge protocols, but such evaluations remain costly: different judges have different prices and reliabilities, and …
We revisit regularized regret minimization under full-information and bandit feedback, where a learner optimizes an objective of the form $\langle r, \pi \rangle - \eta^{-1} …
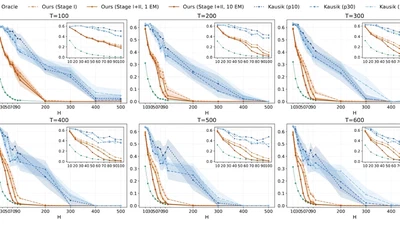
We study the problem of clustering T trajectories of length H, each generated by one of K unknown ergodic Markov chains over a finite state space of size S. The goal is to …
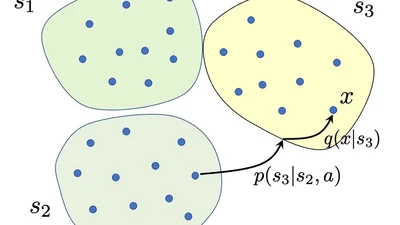
First theoretical analysis of model estimation and reward-free RL of block MDP, without resorting to function approximation frameworks. Lower bounds and algorithms with …