Instance-Optimal Estimation with Multiple LLM Judges on a Budget
Evaluating large language models increasingly relies on LLM-as-a-judge protocols, but such evaluations remain costly: different judges have different prices and reliabilities, and …
Evaluating large language models increasingly relies on LLM-as-a-judge protocols, but such evaluations remain costly: different judges have different prices and reliabilities, and …
We study a new risk-averse bandit setting motivated by semiconductor manufacturing, where the quality of a recipe is judged not by its mean performance but by its weakest outcomes. …
We revisit regularized regret minimization under full-information and bandit feedback, where a learner optimizes an objective of the form $\langle r, \pi \rangle - \eta^{-1} …
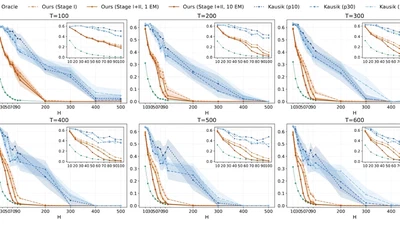
We study the problem of clustering T trajectories of length H, each generated by one of K unknown ergodic Markov chains over a finite state space of size S. The goal is to …

We present GL-LowPopArt, a novel Catoni-style estimator for generalized low-rank trace regression. Building on LowPopArt (Jang et al., 2024), it employs a two-stage approach -- …
Active learning improves training efficiency by selectively querying the most informative samples for labeling. While it naturally fits classification tasks–where informative …
We consider the problem of *regularized* best-response max-regret minimization in online RLHF under general preferences and bandit feedback. While various regularizers are utilized …
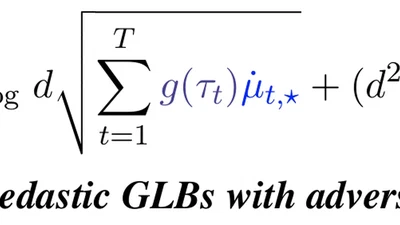
We consider the problem of heteroskedastic generalized linear bandits (GLBs) with adversarial corruptions, which subsumes various stochastic contextual bandit settings, including …
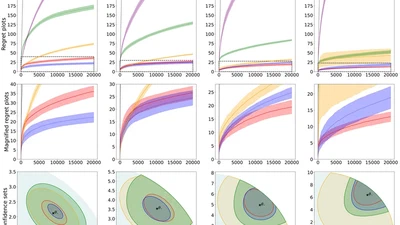
We present a unified likelihood ratio-based confidence sequence (CS) for any (self-concordant) generalized linear model (GLM) that is guaranteed to be convex and numerically tight. …
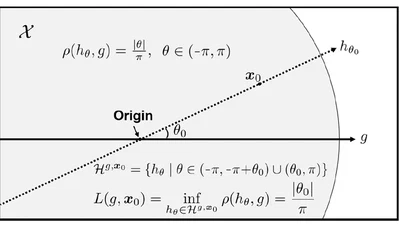
Proposes a new active learning approach by proposing a new uncertainty measure called the least disagree metric, as well as its efficient estimator, which is proven to be …